本文将向您展示如何从 PDF 文档中提取表格(extract tables from PDF documents)。您可能有许多PDF文件,其中包含要单独使用的多个表格。复制(Copying)和粘贴这些表格不是一个好的选择,因为它可能无法提供预期的输出,因此您需要一些其他简单的选项来从PDF文件中提取表格并将这些表格保存为单独的文件。
如果扫描PDF表格,这些PDF 表格提取器工具(PDF table extractor tools)中的大多数都无法提供帮助。在这种情况下,您应该首先使 PDF 可搜索(make the PDF searchable) ,然后尝试这些选项。
从 PDF 文档中提取表格
在这篇文章中,我们添加了 2 个免费在线服务和 3 个免费软件来从PDF文件中提取表格:
- PDF 转 XLS
- PDFtoExcel.com
- 白板
- ByteScout PDF 多功能工具
- Sejda PDF 桌面。
1] PDF转XLS
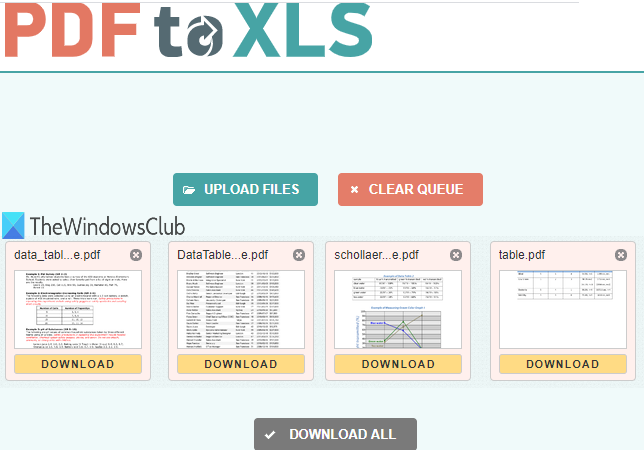
PDF to XLS是从PDF中提取表格的最佳选择之一。它有两个使它很方便的功能。您可以一起从20 个 PDF(20 PDF)文档中获取表格。此外,PDF表格提取是自动的。它将输出生成为XLSX文件。如果PDF有多个表,则每个表分别存储在不同的输出XLSX文件表中。
打开(Open the homepage)此服务的主页。之后,拖放PDF文件或使用上传文件(UPLOAD FILES)按钮。每个上传的PDF都会自动转换为 XLSX 格式文件。输出文件准备好后,您可以一个一个下载它们或下载一个包含所有输出文件的ZIP文件。
2] PDFtoExcel.com

PDFtoExcel.com服务可以一次从一个(PDFtoExcel.com)PDF中提取表格,但它支持多个平台上传PDF。它支持OneDrive、桌面(desktop)、Google Drive和Dropbox平台上传PDF。此外,转换过程是自动的。
该服务主页在这里(here)。在那里,选择一个上传选项来添加PDF。之后,它会自动上传PDF并将其转换为Excel ( XLSX ) 文件。输出准备好后,您将获得下载链接以保存包含PDF表的输出文件。
注意:(Note: )虽然该服务提到它也可以从扫描的PDF文件中提取表格,但它对我不起作用。您仍然可以尝试扫描PDF。
3]白板

Tabula是一款功能强大的软件,可以自动检测PDF中存在的表格,然后让您将这些表格保存为TSV、JSON或CSV文件。您可以选择为每个PDF表格保存单独的(PDF)CSV文件或将所有表格保存在单个CSV文件中的选项。
要下载此开源(open-source)PDF 表格提取器,请单击此处(click here)。它还需要 Java(requires Java)才能成功运行和使用它。
解压您下载的ZIP文件,然后运行tabula.exe文件。它将在您的默认浏览器中打开一个页面。如果页面未打开,则在浏览器中添加 http://localhost:8080 并按Enter。
现在您将看到它的界面,您可以在其中使用“浏览(Browse)”选项添加PDF。之后,按导入(Import)按钮。添加PDF后,您可以在其界面上看到PDF页面。
使用自动检测表格(Autodetect Tables)按钮,它将自动突出显示该PDF中存在的所有表格。您还可以通过选择特定表格手动突出显示表格。如果需要,您还可以删除(remove selected tables)您选择的选定表格。
这将帮助您只保存您想要的那些表。当PDF表格突出显示时,单击预览和导出提取的数据(Preview & Export Extracted Data)按钮。
最后,使用顶部可用的下拉菜单选择输出格式,然后按导出(Export)按钮。这会将PDF表格保存在您选择的输出格式文件中。
4] ByteScout PDF 多功能工具
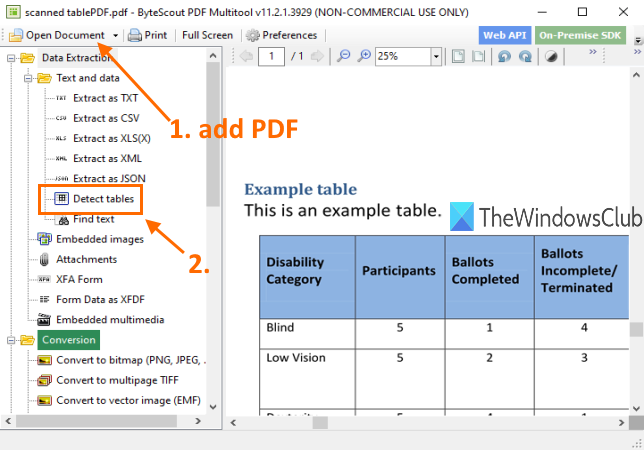
顾名思义,该软件带有多种工具。它具有诸如将 PDF 转换为多页 TIFF(convert PDF to multipage TIFF)、旋转 PDF 文档(rotate PDF document)、使 PDF 不可搜索(make PDF unsearchable)、优化 PDF(optimize PDF)、将图像添加到 PDF(add an image to PDF)等工具。PDF表格检测器功能也在那里,非常棒。此工具的优点是您也可以从扫描的 PDF 中提取表格(extract tables from scanned PDF)。您可以检测多个页面中的表格,然后将这些表格提取为CSV、XLS、XML、TXT或JSON格式文件。在提取之前,它还可以让您设置页面范围(page range)仅从指定页面中提取表。
您可以在此处(here)获取此软件。它仅可免费用于非商业用途(free for non-commercial use)。安装后,运行此软件并使用打开文档(Open Document)选项添加PDF。之后,单击上图中突出显示的检测表工具。(Detect tables)此工具位于数据提取(Data Extraction)类别下。
它将打开一个框,您可以在其中设置检测表的条件。例如,您可以设置最小列数、行数、表格之间的最小换行符、将表格检测模式设置为有边框或无边框表格等。使用选项或保留默认设置。
之后,按该框中的Detect next table按钮。它将识别并选择当前页面上的表格。这样,您可以移动到另一个页面并检测更多表。
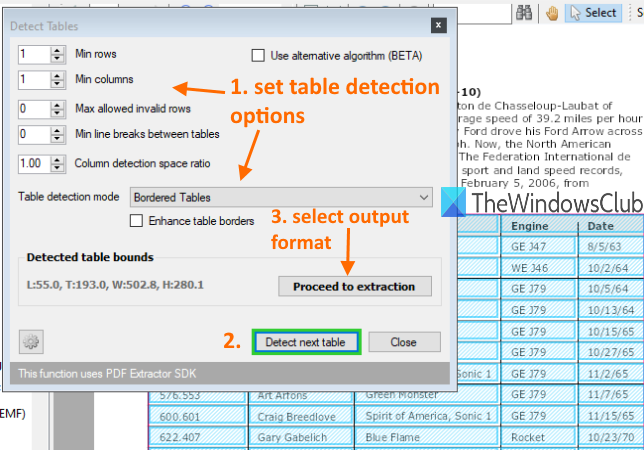
完成后,使用继续提取(Proceed to extraction)按钮,然后选择输出格式。最后,您可以使用选项从当前页面保存表格或定义页面范围,并保存输出。
该工具给出了令人满意的输出。但有时,它可能会检测到PDF中的其他内容,并且可能无法从多个页面中提取表格。在这种情况下,您应该使用它来一张一张地获取和保存表格。
5] Sejda PDF桌面
Sejda PDF Desktop也是一款多用途软件。它可以优化或压缩 PDF(compress PDF),为 PDF 添加水印,从 PDF 中删除限制(remove restrictions from PDF),编辑PDF文档等。但是,它的免费计划有局限性。在免费计划中,每天只能完成 3 个任务。此外,PDF大小限制为50 MB或10 页(10 pages)。
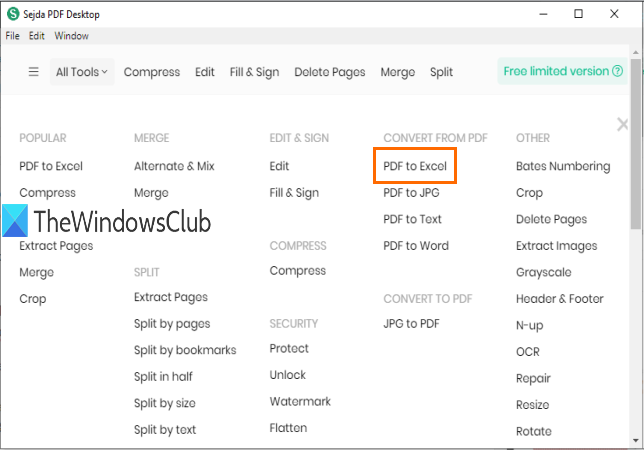
您可以使用其PDF 到 Excel(PDF to Excel)转换工具来提取PDF表格。它会自动检测PDF页面中的表格,并让您将这些表格保存为 XLSX 或CSV。
它的下载链接在这里(here)。安装后,从其主界面使用PDF to Excel工具。(Excel)选择该工具后,使用选择 PDF 文件(Choose PDF files)按钮。免费计划只能添加一份PDF 。
添加PDF后,它将提供将 PDF 转换为 CSV(Convert PDF to CSV)和将 PDF 转换为 Excel(Convert PDF to Excel)按钮。使用一个按钮,然后您可以将输出保存到 PC 上的所需位置。
它的PDF表格检测工具很好。您不必手动检测表。不过,有时它可能会包含其他文本内容作为PDF表格并将其存储在输出中。但总体结果是好的。
就这样。
这些是从PDF(PDF)中提取表格的一些好工具。Tabula软件比其他工具更有效。不过,您可以尝试所有工具并检查哪些工具有帮助。
类似的读法:(Similar reads:)
How to extract Tables from PDF documents
This article will show you hоw to extract tables from PDF documents. You might have many PDF files that contain multiple tables that you want to use separately. Copying and pasting those tables is not a good option as it may not give the expected output, therefore you need some other simple options that can extract tables from a PDF file and save those tables as separate files.
Most of these PDF table extractor tools can’t help if the PDF table is scanned. In such a case, you should first make the PDF searchable and then try these options.
Extract Tables from PDF documents
In this post, we have added 2 free online services and 3 free software to extract tables from a PDF file:
- PDF to XLS
- PDFtoExcel.com
- Tabula
- ByteScout PDF Multitool
- Sejda PDF Desktop.
1] PDF to XLS
PDF to XLS is one of the best options for extracting tables from PDF. It has two features that make it handy. You can fetch tables from 20 PDF documents together. Also, the PDF table extraction is automatic. It generates the output as an XLSX file. If a PDF has multiple tables, then each table is stored separately in different sheets of output XLSX file.
Open the homepage of this service. After that, drag n drop PDF files or use UPLOAD FILES button. Each uploaded PDF is converted to XLSX format file automatically. When the output files are ready, you can download them one by one or download a ZIP file that will contain all the output files.
2] PDFtoExcel.com
PDFtoExcel.com service can extract tables from one PDF at once but it supports multiple platforms to upload PDF. It supports OneDrive, desktop, Google Drive, and Dropbox platforms to upload a PDF. Also, the conversion process is automatic.
This service homepage is here. There, select an upload option to add PDF. After that, it automatically uploads and converts PDF to Excel (XLSX) file. When the output is ready, you will get the download link to save the output file containing PDF table(s).
Note: Though this service mentions that it can extract tables from scanned PDF files also, it didn’t work for me. You can still try it for scanned PDF.
3] Tabula
Tabula is a powerful software that can automatically detect tables present in a PDF and then lets you save those tables as TSV, JSON, or CSV file. You can select the option to save separate CSV files for each PDF table or save all the tables in a single CSV file.
To download this open-source PDF table extractor, click here. It also requires Java to run and use it successfully.
Extract the ZIP file that you downloaded, and run tabula.exe file. It will open a page in your default browser. If the page is not opened, then add http://localhost:8080 in your browser and press Enter.
Now you will see its interface where you can use the Browse option to add a PDF. After that, press Import button. When the PDF is added, you can see PDF pages on its interface.
Use Autodetect Tables button and it will highlight all the tables present in that PDF automatically. You can also manually highlight a table by selecting a particular table. If you want, you can also remove selected tables of your choice.
This will help you save only those tables that you want. When PDF tables are highlighted, click on the Preview & Export Extracted Data button.
Finally, use the drop-down menu available on the top part to select an output format, and press Export button. This will save PDF tables in the output format file selected by you.
4] ByteScout PDF Multitool
As the name suggests, this software comes with multiple tools. It has tools such as convert PDF to multipage TIFF, rotate PDF document, make PDF unsearchable, optimize PDF, add an image to PDF, and more. PDF table detector feature is also there which is pretty awesome. The advantage of this tool is you can extract tables from scanned PDF too. You can detect tables in multiple pages and then extract those tables as CSV, XLS, XML, TXT, or JSON format file. Before extraction, it also lets you set a page range to extract tables from specified pages only.
You can grab this software here. It is free for non-commercial use only. After installation, run this software and use Open Document option to add a PDF. After that, click on the Detect tables tool as highlighted in the image above. This tool is present under Data Extraction category.
It will open a box where you can set conditions to detect tables. For example, you can set a minimum number of columns, rows, minimum line breaks between tables, set table detection mode to bordered or borderless table, etc. Use options or keep the default settings.
After that, press Detect next table button in that box. It will identify and select a table on the current page. In that way, you can move to another page and detect more tables.
When you’re done, use Proceed to extraction button, and select the output format. Finally, you can use options to save the tables from the current page or define a page range, and save the output.
The tool gives a satisfactory output. But sometimes, it might detect other content in PDF, and might not be able to extract tables from multiple pages. In that case, you should use it to fetch and save tables one by one.
5] Sejda PDF Desktop
Sejda PDF Desktop is also a multipurpose software. It can optimize or compress PDF, add watermark to PDF, remove restrictions from PDF, edit PDF document, etc. However, its free plan has limitations. In the free plan, only 3 tasks per day can be done. Also, the PDF size limit is 50 MB or 10 pages.
You can use its PDF to Excel conversion tool to extract PDF tables. It automatically detects the tables in PDF pages and lets you save those tables as XLSX or CSV.
Its download link is here. After installation, use PDF to Excel tool from its main interface. After selecting that tool, use Choose PDF files button. Only one PDF can be added to the free plan.
When the PDF is added, it will provide Convert PDF to CSV and Convert PDF to Excel buttons. Use a button and then you can save the output to the desired location on your PC.
Its PDF table detection tool is good. You don’t have to manually detect tables. Still, sometimes it might include other text content as a PDF table and store it in the output. But overall results are good.
That’s all.
These are some good tools to extract tables from PDF. Tabula software is more effective than other tools. Still, you can try all the tools and check which helps.
Similar reads:
