需要保存网页或网站以便离线查看(Need to save a webpage or website so that you can view it offline)?您是否要长时间离线,但希望能够浏览您喜欢的网站?如果您使用的是Firefox,那么有一个Firefox插件可以解决您的问题。
ScrapBook是一个很棒的Firefox 扩展(Firefox extension),它可以帮助您保存网页(web page)并以非常易于管理的方式组织它们。这个插件最酷的地方在于它非常轻巧、速度快、几乎完美地准确地缓存了网页(web page)的本地副本并支持多种语言。我在几个带有大量图形和精美CSS样式的(CSS)网页上(web page)对其进行了测试,并且非常高兴地看到离线版本看起来与在线版本完全一样。
您可以将ScrapBook用于以下目的:
- 保存单个网页
- (Save snippet or portion)保存单个网页的(Web page)片段或部分
- 保存整个网站
- 以与使用文件夹、子文件夹的书签(Bookmarks)相同的方式组织集合
- 全文(Full text)搜索和快速过滤搜索整个集合
- 编辑收集的网页
- Text/HTML edit类似于 Opera 笔记的文本/HTML 编辑功能
安装剪贴簿
如果您运行的是最新版本的Firefox,在撰写本文时对我来说是 v33,您必须调整一些设置才能正确使用ScrapBook。默认情况下,ScrapBook 图标(ScrapBook icon)不会出现(t show)在任何地方,因此您可以使用它的唯一方法是右键单击网页。通过右键单击工具栏上的任意位置并选择自定义(Customize)将按钮添加到您的工具栏或菜单。

在自定义屏幕上(Customize screen),您会在左侧看到ScrapBook 图标。(ScrapBook icon)继续并将其拖到顶部的工具栏或菜单中。然后继续并单击退出自定义(Exit Customize)按钮。

在我们开始使用ScrapBook保存网站之前,您可能需要更改插件的设置。您可以通过单击右上角的菜单按钮(menu button)(三个水平线)然后单击Add-ons来做到这一点。

现在点击Extensions,然后点击ScrapBook add-on旁边的Options按钮。

您可以在此处更改键盘快捷键、数据存储位置和其他次要设置。

使用 ScrapBook 下载站点
现在让我们深入了解实际使用该程序的细节。首先(First),加载您要下载网页的网站。开始下载的最简单方法是右键单击页面上的任意位置,然后选择菜单底部的“保存页面”(Save Page)或“页面另存为”。(Save Page As)这两个选项是由ScrapBook添加的。

保存页面(Save Page)将让您选择一个文件夹,然后仅自动保存当前页面。如果您想要更多选项,我通常会这样做,请单击“将页面另存(Save Page)为”选项。您将看到另一个对话框,您可以在其中从大量选项中进行选择。
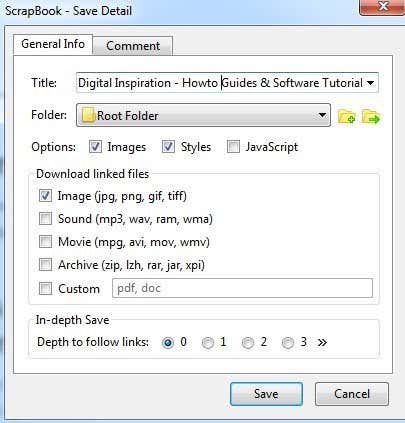
重要部分是选项(Options)、下载链接文件(Download linked files)部分,然后是深度保存(In-depth Save) 选项。默认情况下,ScrapBook会下载图像和样式,但如果网站需要 JavaScript 才能正常运行,您可以添加JavaScript 。
下载(Download)链接文件部分将只下载链接图像,但您也可以下载声音、电影文件、存档文件或指定要下载的文件的确切类型。如果您所在的网站有大量指向特定类型文件(Word 文档(Word docs)、PDF(PDFs)等)的链接,并且您想快速下载所有相关文件,那么这是一个非常有用的选项。
最后,深度保存(In-depth Save)选项是您下载网站大部分内容的方式。默认情况下,它设置为 0,这意味着它不会跟随任何指向网站上其他页面的链接或任何其他链接。如果您选择一个,它将下载当前页面以及(page and everything)从该页面链接的所有内容。Depth of 2 将从当前页面、第一个链接页面以及来自第一个链接页面的任何链接下载。

单击(Click)保存按钮(Save button),将弹出新窗口,页面将开始下载。你会想立即按下暂停(Pause)按钮,让我告诉你为什么。如果您只是让ScrapBook运行,它将开始从页面下载所有内容,包括源代码(source code)中可能链接到一堆其他网站或广告网络的所有内容。如上图所示,在主站点 (labnol.org) 之外,它正在从googleadservices.com 和(googleadservices.com and something)ctrlq.org 下载广告。
您真的希望广告在您离线浏览网站时显示在网站上吗?这也会浪费大量的时间和带宽(time and bandwidth),所以最好的办法是按下暂停(Pause),然后点击过滤(Filter)按钮。

最好的两个选项是Restrict to Domain和Restrict to Directory。通常这些是相同的,但在某些站点上它们会有所不同。如果您确切知道您想要什么页面,您甚至可以按字符串过滤并输入您自己的URL。这个选项非常棒,因为它消除了所有其他垃圾,只从您所在的实际网站下载内容,而不是从社交媒体网站、广告网络等。
继续并单击开始(Start),页面将开始下载。下载时间取决于您的Internet 连接(Internet connection)速度以及您正在下载的网站的确切数量。该插件适用于大多数网站,我遇到的唯一问题是在某些网站上,他们用于链接到自己的内容的 URL 是绝对(URLs)URL(URLs)。
绝对URL(URLs)的问题在于,当您在离线时在Firefox中打开索引页面(index page)并尝试单击任何链接时,它将尝试从实际网站加载,而不是从本地缓存加载。在这些情况下,您必须手动打开下载目录(download directory)并打开页面。这很痛苦,我只在少数几个网站上发生过,但确实发生了。您可以通过单击工具栏上的ScrapBook 按钮(ScrapBook button)然后右键单击该站点并选择(site and choosing)工具(Tools)-显示文件来查看(Show Files)下载文件夹(download folder)。

在资源管理器中,按类型(Type)排序,然后向下滚动到名为HTML 文档的文件。 (HTML Document. )内容页面通常是 default_00x 文件,而不是 index_00x 文件。

如果您没有使用Firefox,但仍想将网页下载到您的计算机,您还可以查看一个名为WinHTTrack的软件,该软件 会自动下载整个网站(web site),以便以后离线浏览。但是,WinHTTrack 会(WinHTTrack)占用大量空间,因此请确保您的硬盘驱动器上有足够的可用空间。
这两个程序都适用于下载整个网站或下载单个网页。实际上,下载整个网站几乎是不可能的,因为WordPress(WordPress)等CMS 软件(CMS software)会生成大量链接。如果您有任何问题,请发表评论。享受!
Download Entire Web Sites in Firefox using ScrapBook
Need to save a webpage or website so that you can view it offline? Are you going to be offline for an extended period of time, but want to be able to browse through your favorite website? If you’re using Firefox, then there is one Firefox add-on that can solve your problem.
ScrapBook is an awesome Firefox extension that helps you to save web pages and organize them in a very easy to manage way. The really cool thing about this add-on is that it’s very light, speedy, accurately caches a local copy of a web page almost perfectly and supports multiple languages. I tested it out on several web pages with a lot of graphics and fancy CSS styles and was surprisingly happy to see that the offline version looked exactly the same as the online version.
You can use ScrapBook for the following purposes:
- Save a single Web page
- Save snippet or portion of a single Web page
- Save an entire Web site
- Organize the collection in the same way as Bookmarks with folders, sub-folders
- Full text search and fast filtering search of the entire collection
- Editing of the collected Web page
- Text/HTML edit feature resembling Opera’s Notes
Installing ScrapBook
If you’re running the latest version of Firefox, which is v33 for me as of this writing, you’ll have to adjust some settings so that you can use ScrapBook properly. By default, the ScrapBook icon won’t show up anywhere, so the only way you can use it is if you right-click on a webpage. Add the button to your toolbar or to the menu by right clicking anywhere on the toolbar and choose Customize.
On the Customize screen, you’ll see the ScrapBook icon on the left-hand side. Go ahead and drag that to either the toolbar at the top or to the menu. Then go ahead and click on the Exit Customize button.
Before we get into using ScrapBook to save a website, you might want to change the settings for the add-on. You can do that by clicking on the menu button at the top right (three horizontal lines) and then clicking on Add-ons.
Now click on Extensions and then click on the Options button next to the ScrapBook add-on.
Here you can change the keyboard shortcuts, the location where the data is stored and other minor settings.
Using ScrapBook to Download Sites
Now let’s get into the details of actually using the program. First, load the website you want to download web pages for. The easiest way to start a download is to right-click anywhere on the page and choose either Save Page or Save Page As towards the bottom of the menu. These two options are added by ScrapBook.
Save Page will let you choose a folder and then automatically save the current page only. If you want more options, which I normally do, then click on the Save Page As option. You’ll get another dialog where you can pick and choose from a whole lot of options.
The important sections are the Options, Download linked files section, and then In-depth Save options. By default, ScrapBook will download images and styles, but you can add JavaScript if a website requires that to work properly.
The Download linked files section will just download linked images, but you can also download sounds, movie files, archive files or specify the exact type of files to download. This is a really useful option if you are on a website that has a bunch of links to a certain type of file (Word docs, PDFs, etc) and you want to download all the associated files quickly.
Lastly, the In-depth Save option is how you would go about download larger portions of a website. By default, it’s set to 0, which means it won’t follow any links to other pages on the site or any other link for that matter. If you choose one, it will download the current page and everything that is linked from that page. Depth of 2 will download from the current page, the 1st linked page and any links from the 1st linked page also.
Click the Save button and new window will pop up and the pages will begin to download. You’ll want to press the Pause button immediately and let me tell you why. If you just let ScrapBook run, it will start to download everything from the page, including all the stuff in the source code that may link to a bunch of other sites or ad networks. As you can see in the image above, outside of the main site (labnol.org), it’s downloading ads from googleadservices.com and something from ctrlq.org.
Do you really wants the ads to show up on the site while you’re browsing it offline? This will also waste a lot of time and bandwidth, so the best thing to do is to press Pause and then click on the Filter button.
The best two options are Restrict to Domain and Restrict to Directory. Normally these are the same, but on certain sites they will be different. If you know exactly what pages you want, you can even filter by string and type in your own URL. This option is fabulous because it gets rid of all the other junk and only downloads content from the actual website you’re on rather than from social media sites, ad networks, etc.
Go ahead and click Start and the pages will start to download. The time to download will depending on your Internet connection speed and exactly how much on the website you are downloading. The add-on works great for most sites and the only issue that I have run into is that on some sites, the URLs they use for linking to their own content are absolute URLs.
The problem with absolute URLs is that when you open the index page in Firefox while offline and try to click on any of the links, it will try to load from the actual website rather than from the local cache. In those cases, you have to manually open the download directory and open the pages. It’s a pain and I’ve only had it happen on a handful of sites, but it does occur. You can view the download folder by clicking on the ScrapBook button on your toolbar and then right clicking on the site and choosing Tools – Show Files.
In Explorer, sort by Type and then scroll down to the files called HTML Document. The content pages are normally the default_00x files, not the index_00x files.
If you’re not using Firefox and still want to download webpages to your computer, you can also check out a software called WinHTTrack that will automatically download an entire web site for later browsing offline. However, WinHTTrack uses up a good amount of space, so make sure you have enough free space on your hard drive.
Both programs works well for downloading entire websites or for downloading single webpages. In practice, downloading an entire website is almost impossible because of the massive number of links that are generated by CMS software like WordPress, etc. If you have any questions, post a comment. Enjoy!
