什么是网页抓取以及它在数字世界中的工作方式
数据(Data)和信息是两个经常互换使用的术语,但它们之间存在显着差异。例如,数据指的是信息位,而不是信息本身。另一方面,信息(Information)是一组以有意义的方式处理的数据。随着互联网上可用的大量数据,Web Scraping、Web Harvesting或Web Data Extraction等不同的方法被用于生成关于互联网(Internet)使用的可操作和改变游戏规则的见解。但它们在网络世界中究竟意味着什么。让我们来看看!
网页抓取是如何工作的
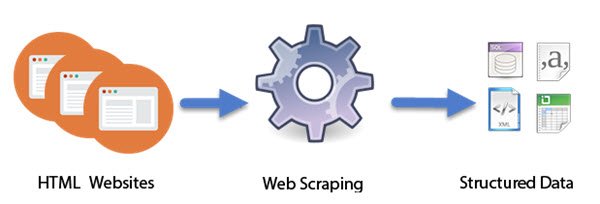
(Computer)设计为智能(Intelligent)机器人的计算机程序执行Web Scraping的工作。与仅复制屏幕上显示的像素的屏幕抓取不同,网络抓取提取底层HTML代码,并通过它提取存储在数据库中的数据。这种方法已经非常流行。事实上,它被认为是在当今数字世界中获得的基本技能之一。它在编译大型数据集方面有一些很好的应用,这些技术是以下技术的基础:
随着数字信息的快速扩展,通过Web Scraping或Web Data Extraction方法访问(Web Data Extraction)大数据(Big Data)变得更加容易。话虽如此,Web Scraping可用于在(Web Scraping)合法(Legitimate)或非法情况下依赖数据收集的数字业务。前者包括仁慈的网络抓取示例(Benevolent Web Scraping Examples),而后者则包含恶意网络抓取(Malicious Web Scraping)示例。
仁慈的网络抓取示例
- 搜索(Search)引擎机器人抓取网站,分析其内容以根据某些发现分配排名,例如Google。
- 价格(Price)比较网站部署机器人来自动获取产品价格
- 市场(Market)研究公司使用抓取工具从社交媒体中提取数据(例如,用于情绪分析、个人偏好等)。
恶意网页抓取示例
(Web Scraping)如果未经网站所有者许可提取数据,则出于非法目的进行网络抓取可能会造成严重的经济损失。恶意网页抓取(Malicious Web Scraping)最常见的两个用例是价格抓取和内容盗窃。
- Price Scraping – Scraper机器人检查竞争的业务数据库以访问定价信息,削弱竞争对手并促进销售。
- 内容盗窃(Content Theft) ——这种非法活动包括从目标网站上进行的大规模内容盗窃。典型目标主要包括在线产品目录和依靠数字内容驱动业务的网站。
希望这可以帮助!

About the author
我是一名硬件工程师,拥有超过 10 年的 IOS 和 MacOS 系统工作经验。在过去的 5 年里,我也是一名夜班老师,并且自学了如何使用 Google Chrome。我在这两个领域的技能使我成为网站开发、图形设计或网络安全工作的完美人选。
Related posts
没有Internet Connectivity,但显示与Web相连
什么是Bitcoin,Digital Currency
D8337646 Accounts Digital Assets Management
什么是Dark Web or Deep Web?如何Access & Precautions
服用Digital Detox的好处以及如何实现它
Domain Fronting和危险和危险解释
Santa Claus现在在哪里? Santa Claus tracker网站将为您提供帮助
什么是403 Forbidden Error and How修复它?
如何在Windows 10中添加Trusted Site
Online Reputation Management Tips,Tools & Services
Service Attacks DDoS Distributed Denial:保护,Prevention
使用Group Policy禁用Internet Explorer 11作为standalone browser
如何疏通和访问Blocked或受限网站
Screamer Radio是Windows PC的体面Internet Radio app
10 Web 3.0 示例:它是互联网的未来吗?
检查您的Internet Connection是否能够流媒体4K内容
31 款最佳网页抓取工具
Internet Security article and tips用于Windows 10用户
如何建立一个Internet connection在Windows 11/10
Windows 10 Best免费Internet Security Suite Software