我们很多人都经历过硬盘或 SSD 故障。我们中的一些人甚至试图更多地了解硬盘的可靠性及其隐藏的预测功能,这是一种称为(hidden prediction function)SMART的技术的一部分。有人可能会争辩说,SMART并不可靠,因为它不能在所有情况下都预测失败。这个事实部分是正确的,但是这个自我监控系统的实际内部工作并不是那么简单,所以让我们来看看SMART是如何工作的。我们还将向您展示如何检查HDD SMART 状态(HDD SMART status)以及固态驱动器SMART 状态(SMART status):
什么是 SMART(HDD 和 SSD)?
SMART 是一个监控驱动器内部信息的系统。(SMART is a system that monitors the internal information of your drive.)它聪明的名字(clever name)实际上是Self-Monitoring, Analysis, and Reporting Technology的首字母缩写。SMART,也写作SMART,是一种在HDD 和 SSD(HDDs and SSDs)中发现的技术。它独立于您的操作系统(operating system)、BIOS或其他软件。
SMART对HDD 和 SSD(HDDs and SSDs)有什么作用?
SMART的发明是因为计算机需要能够监控其硬盘驱动器健康状态的东西。(health state)这意味着,简单地说,SMART 应该能够告诉您您的硬盘驱动器或固态驱动器是否即将停止工作(SMART should supposedly be able to tell you if your hard drive or solid-state drive is about to stop working)!

SMART如何做到这一点?您可能会认为SMART可以神奇地猜测您的驱动器是否健康。🙂 不过,它的作用完全不同。SMART 跟踪一系列变量,这些变量(SMART keeps track of a series of variables)的数量和类型因驱动器而异,这是其可靠性的指标(indicators of its reliability)。如果您想深入了解所有SMART属性,大约有 50 个(原始读取错误率(error rate)、启动时间、报告的不可纠正错误、开机时间、加载循环计数(cycle count)等) ,访问这个网页(visit this webpage)。
但是,要知道,除了一些单一的尝试(Google、Backblaze)之外,大多数SMART . 数据未记录。该系统提供了大量的内部数据。尽管如此,由于许多硬盘制造商使用不同的定义和测量方法,统计数据仍存在许多不一致之处。例如,一些制造商将通电时间数据存储为小时,而其他制造商则以分钟或秒为单位进行测量。此外,它们没有解释哪些属性或变量值得我们关注,使我们淹没在数据中。
在尝试了解哪些SMART属性是相关的之前,我们首先必须区分SSD 和 HDD 故障的主要类型:可预测和不可预测(SSD and HDD failures: predictable and non-predictable)。

可预测(Predictable failures)的故障包括及时出现的故障,由磁盘机械故障或硬盘表面损坏引起的故障。对于固态驱动器,可预测的故障可能包括随时间推移的正常磨损或失败的大量擦除尝试。随着时间的推移,问题会变得更糟,驱动器最终会出现故障。(Problems)
不可预知的故障(Non-predictable failures)是由突发事件引起的,其中我们可以提到,例如突然的电源浪涌或硬盘或固态驱动器内部电路的意外损坏。重要的是要了解SMART 只能帮助您检测可预测的故障(S.M.A.R.T. can only help you detect predictable failures)。
现在您已经对SMART是什么以及做什么有了基本的了解,让我们看看如何从Windows检查驱动器的SMART 状态(SMART status),以及如何阅读和解释SMART详细信息:
如何检查SSD 和 HDD SMART 状态(SSD and HDD SMART status)
在Windows计算机和设备上,从硬盘或SSD读取(SSD)SMART数据的最简单方法是使用专门的应用程序。那里有很多,但其中许多要么发展不善,要么花钱(cost money)。在所有可以读取SMART数据的应用程序中,最好的也是我们推荐您使用的应用程序是CrystalDiskInfo。它是免费的,能够读取SMART属性,它也是少数可以同时从IDE ( PATA )、SATA和NVMe获取(NVMe)SMART数据的应用程序之一(SMART)驱动器,以及使用 e SATA、USB或IEEE 1394的便携式驱动器。

检查HDD 或 SSD的(HDD or SSD)SMART 状态和详细信息(SMART status and details)的另一种极好的方法是使用其制造商提供的应用程序。例如,大多数固态驱动器都附带支持应用程序(support apps),可让您检查有关它们的信息、检查它们的运行状况、运行诊断程序等。这些应用程序通常包括检查SMART 状态(SMART status)的选项。
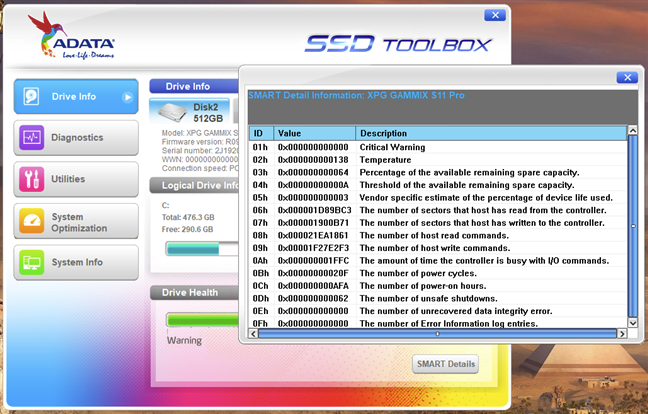
Windows 10提供了第三种检查硬盘驱动器或 SSD (disk drive or SSD)SMART 状态(SMART status)的方法。它不显示详细信息,但可以告诉您驱动器的SMART 状态是否正常。(SMART status)要检查SMART,请打开命令提示符(Command Prompt)并运行以下命令:wmic diskdrive get model, status。该命令输出连接到 PC 的驱动器列表并显示每个驱动器的SMART 状态(SMART status)。
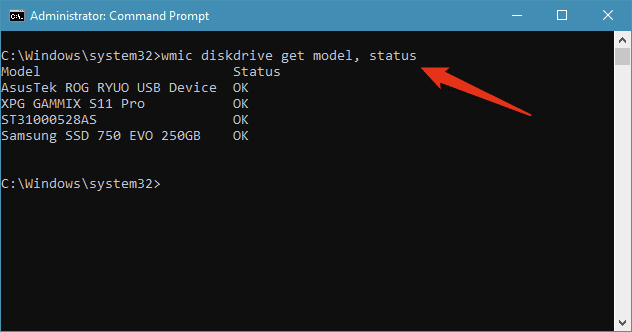
检查SMART 状态(SMART status)的最后一种方法可能是Windows 10中检查驱动器是否出现故障的最快方法。
如何运行 SSD 或 HDD SMART 测试
如果您对仅读取驱动器的SMART 状态(SMART status)不满意,您还可以运行SSD 或 HDD SMART 测试(SSD or HDD SMART test)。说起来容易做起来难,因为您需要为此目的使用专门的应用程序。因此,我们认为这是一个值得单独写一篇文章的主题,您可以通过以下链接访问:测试您的HDD 或 SSD(HDD or SSD)并检查其健康状态(health status)。
如何读取SMART值和属性
通过多个传感器持续测试和监控硬盘的健康状态。(health status)通过使用典型算法测量值,然后根据结果调整相应的属性。
在任何 SMART监控程序(monitoring program)中,您都应该看到至少包含以下部分字段的属性:
-
标识符:(Identifier:)属性的定义。它通常有一个标准的含义,用 1 到 250 之间的数字标记(例如 9 是Power-on Count)。尽管如此,所有磁盘监视和测试工具(disk monitoring and testing tools)都提供了属性的名称和文本描述。
-
阈值:(Threshold:)属性的最小值。如果达到此值,则您的驱动器即将发生故障。
-
值:(Value:)属性的当前值。该算法根据原始数据计算此数字。一个新的硬盘驱动器应该有一个很大的数字,即理论最大值(100、200 或 253,具体取决于制造商),该数字在其生命周期内会减少。
-
最差:(Worst:)有史以来记录的属性的最小值。
-
数据:(Data:)传感器或计数器提供的原始测量值。这是HDD 或 SSD(HDD or SSD)制造商设计的算法使用的数据。其内容取决于驱动器的属性和制造商。普通用户应该跳过这个。
-
Flags:属性的用途。这通常由制造商设置,因此因(manufacturer and therefore varies)驱动器而异。每个属性要么是关键的,可以预测即将发生的故障(例如,ID 5重新分配的扇区计数),要么是对状态没有直接影响的统计数据(例如,ID 174意外断电计数(power loss count))。

当试图了解任何 SMART 属性的状态时,请检查这三个字段的值:值、阈值和标志(to understand the status of any S.M.A.R.T. attribute, check the values of these three fields: value, threshold, and flags)。另外,请记住,通常,较小的值表示可靠性降低(smaller values are an indication of a decrease in reliability)。
如何使用SMART预测HDD 或 SSD(HDD or SSD)的故障(检查的基本值)
并非所有SMART。属性对于故障预测(failure prediction)至关重要。上述两项关于硬盘故障(drive failure)率的研究和其他来源一致认为,识别故障驱动器的重要帮助是:
-
重新分配的扇区计数(Reallocated sector counts)。当驱动器的逻辑将由于反复出现的软错误或硬错误而损坏的扇区从其备用扇区重新映射到新的物理扇区时,就会发生重新分配。该属性反映了重新映射发生的次数。如果其值增加,则表明 HDD 或 SSD 磨损。
-
当前待定扇区计数(Current Pending Sector Count)。这会计算“不稳定”扇区,即具有读取错误且正在等待重新映射的损坏扇区,这是一种“试用”系统。SMART 算法对这一特定属性的理解参差不齐,因为它有时无法令人信服。尽管如此,它仍可以对可能出现的问题提供早期警告。
-
报告无法纠正的错误(Reported Uncorrectable Errors)。它是无法恢复的错误计数,它很有用,因为它似乎对所有制造商都具有相同的含义。
-
擦除失败计数(Erase Fail Count)。这是固态驱动器过早死亡的一个很好的指标。它计算失败的数据删除尝试次数,增加的值告诉您 SSD 内的闪存接近其使用寿命。
-
磨损均衡计数(Wear Leveling Count)。这对于 SSD 也特别有用。制造商在其 SMART 数据中设置了 SSD 的预期寿命。磨损均衡计数(Wear Leveling Count)是对驱动器健康状况的估计。它是使用一种算法计算的,该算法考虑了预定义的预期寿命和每个内存闪存块在达到其寿命结束之前可以执行的周期数(写入、擦除等)。
-
磁盘温度(Disk temperature)是一个备受争议的参数。尽管如此,人们认为高于 60°C 的值会降低 HDD 或 SSD 的使用寿命并增加损坏的可能性。我们建议使用风扇来降低驱动器的温度,并有望延长其使用寿命。
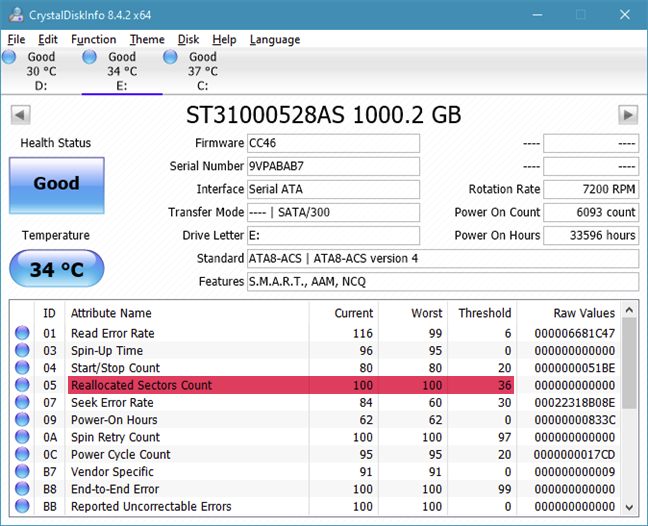
上面提到的SMART。属性相对容易解释。如果您注意到它们的值增加,则您的驱动器可能出现故障,因此您最好开始备份。但是,尽管这些是驱动器可靠性的有用指标,但不要忘记它们并非万无一失。
关于 SMART 的历史记录
SMART是从1992 年(year 1992)开始开发的,尽管您现在知道它已包含在所有现代固态驱动器和硬盘驱动器中。它的历史涵盖了一系列名称,例如Predictive Failure Analysis 或 IntelliSafe(Predictive Failure Analysis or IntelliSafe),以及来自所有主要硬盘制造商的输入:IBM、Seagate、Quantum、Western Digital。最后,它的文档在 2004 年首次出现在Parallel ATA标准中,之后定期进行修订。最新一期是 2011 年发行的。
关于SSD 和 HDD SMART,(SSD and HDD SMART)您还有什么想了解的吗?
这是我们对SMART(S.M.A.R.T)内部工作原理及其监控、测试和预测硬盘故障的能力的简短研究。您应该记住的主要观点是,此自我监控系统可以帮助您查看HDD的(HDD)健康状况(health status)。如果您想使用此SMART 数据(S.M.A.R.T data)来查看您自己的驱动器是否有问题,请阅读我们在本教程中推荐的文章。另外,如有问题,请使用下面的评论表,让我们讨论。
What is SMART and how to use it to predict HDD or SSD failure
A lot of us have experiencеd a hard disk or an SSD failure. Some of us have even tried to find out more about the reliability of hard drives and their hiddеn predіction function that's part of a tеchnology called SMART. One might argue that SMART is not as reliable as it does not predіct fаilure in all cases. This fact is partly true, but the actual inner workings of this self-monitoring system аre not so simple, so let's еxamіne how SMART works. We're also going to show you how to check the HDD SMART status, as well as the solid-state drive SMART status:
What is SMART (HDD & SSD)?
SMART is a system that monitors the internal information of your drive. Its clever name is actually an acronym for Self-Monitoring, Analysis, and Reporting Technology. SMART, also written as S.M.A.R.T., is a technology found inside HDDs and SSDs. It is independent of your operating system, BIOS, or other software.
What does SMART do for HDDs and SSDs?
SMART was invented because computers needed something that could monitor the health state of their hard drives. That means, plainly speaking, that SMART should supposedly be able to tell you if your hard drive or solid-state drive is about to stop working!
How does SMART do that? You might be tempted to think that SMART can magically guess if your drive is healthy. 🙂 What it does is an entirely different story, though. SMART keeps track of a series of variables whose number and type vary from drive to drive, which are indicators of its reliability. If you want to get an in-depth idea of all the SMART attributes, as there are about 50 of them (raw read error rate, spin-up time, reported uncorrectable errors, power-on time, load cycle count, etc.), visit this webpage.
However, know that, apart from some singular attempts (Google, Backblaze), most of the S.M.A.R.T. data is undocumented. The system provides a great deal of internal data. Still, there are many inconsistencies in the statistics because many of the hard drive manufacturers use different definitions and measurements. For example, some manufacturers store power on-time data as hours, while others measure it in minutes or seconds. Also, they don't explain which of the various attributes or variables are worth our attention, making us drown in data.
Before attempting to understand which SMART attributes are relevant, we first have to differentiate between the main types of SSD and HDD failures: predictable and non-predictable.
Predictable failures include the breakdowns that appear in time and are caused by faulty disk mechanics or damages of the disk's surface in the case of hard-disks. For solid-state drives, predictable failures can include normal wear over time or a high number of erasing attempts that have failed. Problems get worse over time, and the drive eventually fails.
Non-predictable failures are caused by sudden events, of which we can mention, for example, sudden power surges or unexpected damage to circuitry inside the hard disk or solid-state drive. What is important to understand is that S.M.A.R.T. can only help you detect predictable failures.
Now that you have a basic understanding of what SMART is and does, let's see how to check the SMART status of your drives from Windows and then also how to read and interpret the SMART details:
How to check SSD and HDD SMART status
On Windows computers and devices, the easiest way to read SMART data from a hard disk or from an SSD is by using specialized apps. There are quite a few out there, but many of them are either poorly developed or cost money. Out of all the apps that can read SMART data, the best and the one that we're recommending that you use is CrystalDiskInfo. It is free, able to read SMART attributes, and it's also one of the few such apps that can get SMART data both from IDE(PATA), SATA, and NVMe drives, as well as from portable drives that are using eSATA, USB, or IEEE 1394.
Another excellent method of checking the SMART status and details of an HDD or SSD is to use the apps provided by its manufacturer. For example, most solid-state drives are accompanied by support apps that let you check information about them, check their health, run diagnostics, and so on. These apps usually include options for checking SMART status.
A third way of checking the SMART status of your hard disk drive or SSD is offered by Windows 10. It doesn't show details, but can tell you whether the SMART status of your drives is OK or not. To check SMART, open Command Prompt and run this command: wmic diskdrive get model, status. The command outputs the list of drives connected to your PC and shows the SMART status for each of them.
This last method to check the SMART status is probably the quickest way in Windows 10 to check whether your drives are failing.
How to run an SSD or HDD SMART test
If you're not satisfied with just reading the SMART status of your drives, you can also run an SSD or HDD SMART test. That is easier said than done because you need a specialized app for this purpose. Accordingly, we considered that this is a subject worthy of a separate article, which you can access via this link: Test your HDD or SSD and check its health status.
How to read SMART values and attributes
The health status of the hard disk is continuously tested and monitored with multiple sensors. The values are measured by the use of typical algorithms, and then the corresponding attributes are tweaked according to the results.
In any SMART monitoring program, you should see attributes that contain at least some of these fields:
-
Identifier: the definition of the attribute. It usually has a standard meaning, and it is marked with a number between 1 and 250 (for example, 9 is Power-on Count). Still, all disk monitoring and testing tools provide the name and a textual description of the attribute.
-
Threshold: the minimum value for the attribute. If this value is reached, then your drive is about to fail.
-
Value: current value of the attribute. The algorithm calculates this number based upon the raw data. A new hard drive should have a high number, the theoretical maximum (100, 200, or 253 depending on the manufacturer), that decreases during its lifetime.
-
Worst: the smallest value of the attribute ever recorded.
-
Data: raw measured values provided by a sensor or a counter. This is the data used by the algorithm designed by the manufacturer of the HDD or SSD. Its contents depend on the attribute and the maker of the drive. Regular users should skip this one.
-
Flags: the purpose of the attribute. This is usually set by the manufacturer and therefore varies from drive to drive. Each of the attributes is either critical and can predict an imminent failure (for example, ID 5 reallocated sectors count), or statistical with no direct effect on status (for example, ID 174 unexpected power loss count).
When trying to understand the status of any S.M.A.R.T. attribute, check the values of these three fields: value, threshold, and flags. Also, remember that, usually, smaller values are an indication of a decrease in reliability.
How to use SMART to predict the failure of an HDD or SSD (essential values to check)
Not all S.M.A.R.T. attributes are critical for failure prediction. The two above mentioned studies on hard drive failure rates and other sources agree that an important help in identifying failing drives are:
-
Reallocated sector counts. Reallocation happens when the drive's logic remaps a damaged sector, as a result of recurring soft or hard errors, to a new physical sector from its spare ones. This attribute reflects the number of times a remapping has happened. If its value increases, it's an indication of HDD or SSD wear.
-
Current Pending Sector Count. This counts the "unstable" sectors, meaning the damaged ones with read errors that are waiting for a remapping, a kind of "probation" system. S.M.A.R.T. algorithms have mixed understandings about this particular attribute, as it is sometimes unconvincing. Still, it can provide an earlier warning of possible problems.
-
Reported Uncorrectable Errors. It is the count of errors that are impossible to recover, and it is useful because it seems to have the same meaning for all manufacturers.
-
Erase Fail Count. This one is an excellent indicator of the premature death of a solid-state drive. It counts the number of failed data deletion attempts, and a value that increases tells you that the flash memory inside the SSD is close to its end-of-life.
-
Wear Leveling Count. This is also especially useful for SSDs. Manufacturers set the expected lifetime of an SSD in its SMART data. The Wear Leveling Count is an estimation of the health of your drive. It is calculated using an algorithm that takes into account the predefined expected lifetime and the number of cycles (write, erase, etc.) that each memory flash block can perform before reaching its end-of-life.
-
Disk temperature is a highly debated parameter. Still, it is considered that values above 60°C can reduce the lifespan of an HDD or SSD and increase the probability of damage. We recommend using a fan to decrease the temperature of your drives and hopefully prolong their life.
The above mentioned S.M.A.R.T. attributes are relatively easy to interpret. If you notice an increase in their values, it is possible that your drive is failing, so you'd better start backing up. However, although these are useful indicators of drive reliability, do not forget that they are not foolproof.
Historical note about SMART
SMART was developed beginning with the year 1992, although you know now that it is included by all modern solid-state drives and hard disk drives. Its history covers an array of names like Predictive Failure Analysis or IntelliSafe and input from all the major hard disk manufacturers: IBM, Seagate, Quantum, Western Digital. Finally, its documentation was featured for the first time in 2004 within the Parallel ATA standard and received regular revisions afterward. The latest one was issued in 2011.
Is there anything else you would like to know about SSD and HDD SMART?
This was our short study on the inner workings of S.M.A.R.T and its abilities to monitor, test, and predict hard disk failures. The main point of view you should remember is that this self-monitoring system can help you review the health status of your HDD. If you want to use this S.M.A.R.T data to see if your own drive has problems, read the articles we recommended in this tutorial. Also, for questions, use the comments form below, and let's discuss.
